Это перевод статьи Бассима Эледата «8 Levels of Agentic Engineering».
ИИ умеет писать код быстрее, чем мы умеем это использовать. Вот почему рекорды на SWE-bench так расходятся с реальной продуктивностью, на которую смотрит руководство. Когда одна команда выпускает Cowork за 10 дней, а другая застревает на сломанном прототипе с теми же моделями — разница не в инструментах. Разница в том, умеют ли ими пользоваться.
Этот разрыв не закрывается за ночь. Он закрывается по уровням. Их восемь.
Скорее всего, первые несколько уровней вы уже прошли. Стремитесь к следующему: каждый даёт огромный прирост продуктивности, и с каждым улучшением моделей этот прирост только растёт.
Есть ещё одна причина — эффект мультиплеера. Ваша продуктивность зависит от уровня коллег сильнее, чем кажется. Допустим, вы — маг 7-го уровня: пока вы спите, фоновые агенты выдают качественные PR. Но если репозиторий требует одобрения коллеги на 2-м уровне, который проверяет код вручную, — ваша пропускная способность буксует. Поэтому тянуть команду вверх — в ваших прямых интересах.
Общаясь с разными командами и разработчиками, которые работают с ИИ, я вижу такую прогрессию — не строго последовательную:
8 уровней агентной инженерии

Уровни 1 и 2: Автодополнение по Tab и агентные IDE
Эти два уровня пробегу быстро — в основном для исторической полноты. Можно листать дальше.
Всё начиналось с Copilot и автодополнения по Tab. Нажал Tab — код дополнился. Большинство уже это переросли или вовсе начали с более высоких уровней. Подход работал лучше для опытных разработчиков — тех, кто умел набросать скелет кода, а ИИ его заполнял.
AI-ориентированные IDE вроде Cursor изменили правила игры: чат к кодовой базе, многофайловые правки стали намного удобнее. Но потолок всегда упирался в контекст. Модель помогала только с тем, что видела, — а видела она либо не то, либо слишком много лишнего.
На этом уровне все начинают экспериментировать с режимом планирования (plan mode): грубая идея → структурированный план для LLM → итерации → реализация. Работает хорошо и даёт контроль над процессом. На поздних уровнях зависимость от режима планирования сходит на нет — но об этом позже.
Уровень 3: Инженерия контекста
Главный термин 2025 года. Инженерия контекста стала важной, когда модели научились стабильно выполнять инструкции при достаточном, но не раздутом контексте.
Зашумлённый контекст работал не лучше пустого — поэтому все занялись информационной плотностью каждого токена. «Каждый токен должен бороться за своё место в промпте» — таков был принцип. Тот же смысл, меньше токенов.
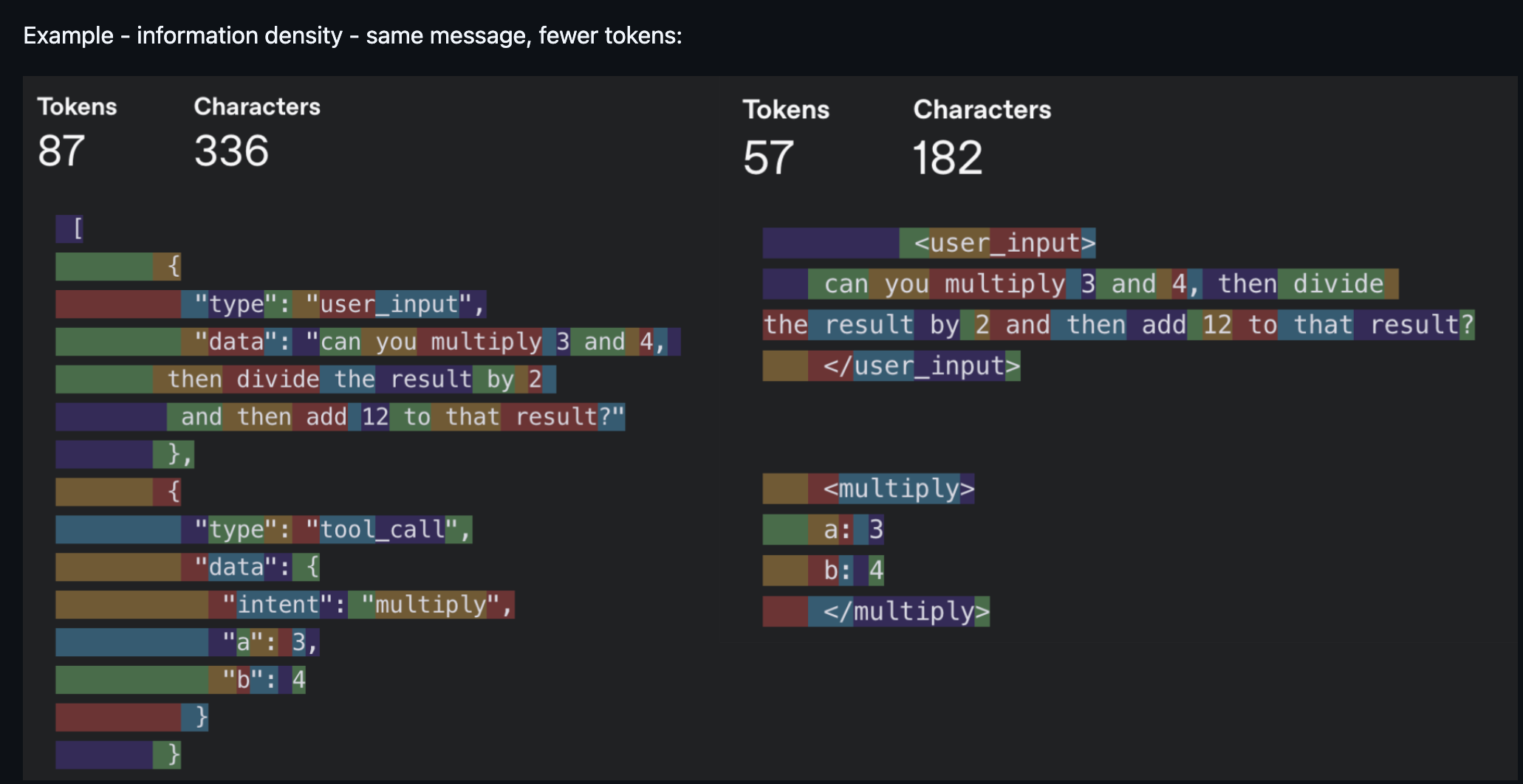
На практике инженерия контекста захватывает больше, чем кажется:
- Это ваш системный промпт и файлы правил (.cursorrules, CLAUDE.md).
- Это описания инструментов — модель читает их, чтобы понять, какой вызвать.
- Это управление историей диалога: долго работающий агент не должен терять нить на десятом шаге.
- Это выбор инструментов, видимых на каждом шаге: слишком много вариантов перегружает модель так же, как и человека.
Сейчас об инженерии контекста говорят реже. Модели стали терпимее к шумному контексту и умеют работать в более хаотичных условиях — большие контекстные окна тоже помогли. Но следить за тем, что ест контекст, по-прежнему важно. Несколько случаев, где это критично:
- Маленькие модели чувствительнее к контексту. Голосовые приложения часто работают на небольших моделях, а размер контекста напрямую влияет на время до первого токена — и на задержку.
- Прожорливые инструменты и модальности. MCP-серверы вроде Playwright и визуальные данные быстро сжигают токены — и сжатие контекста в Claude Code наступает раньше, чем ожидаешь.
- Агенты с десятками инструментов: модель тратит больше токенов на разбор схем, чем на реальную работу.
Инженерия контекста никуда не делась — она эволюционировала. Акцент сместился с «убери лишнее» на «убедись, что нужное есть в нужный момент». Именно этот сдвиг готовит почву для уровня 4.
Уровень 4: Накопительная инженерия
Инженерия контекста улучшает текущую сессию. Накопительная инженерия улучшает каждую следующую.
Концепция, популяризированная Кираном Клаассеном, стала переломным моментом — и для меня, и для многих других. Это осознание того, что вайб-кодинг способен на гораздо большее, чем просто прототипы.
Это цикл: планируй, делегируй, оценивай, кодифицируй. Планируете задачу с достаточным контекстом. Делегируете. Оцениваете результат. И — главное — кодифицируете выводы: что сработало, что сломалось, какой паттерн использовать в следующий раз.

Шаг кодификации и создаёт эффект накопления. LLM не помнят прошлых сессий. Если модель вчера вернула зависимость, которую вы явно удалили, завтра она сделает то же самое — если не сказать ей не делать этого. Самый простой способ замкнуть цикл — обновить CLAUDE.md или аналогичный файл правил, чтобы урок закрепился в каждой следующей сессии.
Предостережение: если кодифицировать всё подряд, это обернётся против вас. Слишком много инструкций — всё равно что никаких. Лучший вариант — среда, где LLM может сама находить нужный контекст: например, актуальная папка docs/ (подробнее на уровне 7).
Те, кто практикует накопительную инженерию, очень внимательно относятся к тому, какой контекст видит LLM. Когда LLM ошибается — они сначала ищут недостающий контекст, а не обвиняют модель. Именно этот инстинкт открывает путь к уровням 5–8.
Уровень 5: MCP и навыки
Уровни 3 и 4 решают проблему контекста. Уровень 5 решает проблему возможностей.
MCP-серверы и кастомные навыки дают LLM доступ к вашей базе данных, API, CI-пайплайну, дизайн-системе, к Playwright для тестирования в браузере, к Slack для уведомлений. Модель перестаёт просто думать о кодовой базе — она начинает в ней действовать.
О MCP и навыках написано достаточно, не буду повторяться. Лучше расскажу, как использую их сам. Мы с командой делим общий навык ревью PR — он запускает подагентов в зависимости от характера изменений:
- Один отвечает за безопасность интеграции с базой данных.
- Другой анализирует сложность: ищет избыточности и переусложнение.
- Третий проверяет промпты на соответствие командным стандартам.
- Также запускаются линтеры и Ruff.

Зачем вкладываться в навык ревью? Потому что, когда агенты начинают генерировать PR в промышленных масштабах, узким местом становится ручное ревью, а не качество кода. На смену приходит автоматизированное, единообразное ревью на основе навыков.
Из MCP: использую Braintrust MCP, чтобы LLM могла запрашивать логи оценок и вносить изменения напрямую. И DeepWiki MCP — он даёт агенту доступ к документации любого open-source репозитория без ручного переноса контекста.
Когда несколько людей пишут собственные версии одного навыка, имеет смысл объединить их в общий реестр. Block описывали свой подход: внутренний маркетплейс навыков, более 100 штук, курируемые наборы для ролей и команд. Навыки получают то же отношение, что и код — PR, ревью, версионирование.
Ещё одна тенденция: LLM всё чаще используют CLI-инструменты вместо MCP (каждая компания, кажется, уже выпустила свой: Google Workspace CLI, Braintrust тоже на подходе). Причина — экономия токенов. MCP-серверы добавляют полные схемы инструментов в контекст на каждом шаге, даже если агент их не использует. CLI работают иначе: агент выполняет конкретную команду, и в контекстное окно попадает только релевантный вывод.
Важное замечание. Уровни 3–5 — фундамент для всего дальнейшего. LLM непредсказуемо хороши в одних вещах и плохи в других. Нужно выработать интуицию по этим границам, прежде чем наращивать автоматизацию. Если контекст зашумлён, промпты недоопределены, инструменты плохо описаны — уровни 6–8 только усилят хаос.
Уровень 6: Инженерия окружения и циклы обратной связи
Вот где ракета действительно начинает взлетать.
Инженерия контекста — это про то, что видит модель. Инженерия окружения — про среду, инструментарий и циклы обратной связи, которые позволяют агентам работать надёжно без вашего участия.
Дайте агенту цикл обратной связи, а не просто редактор.
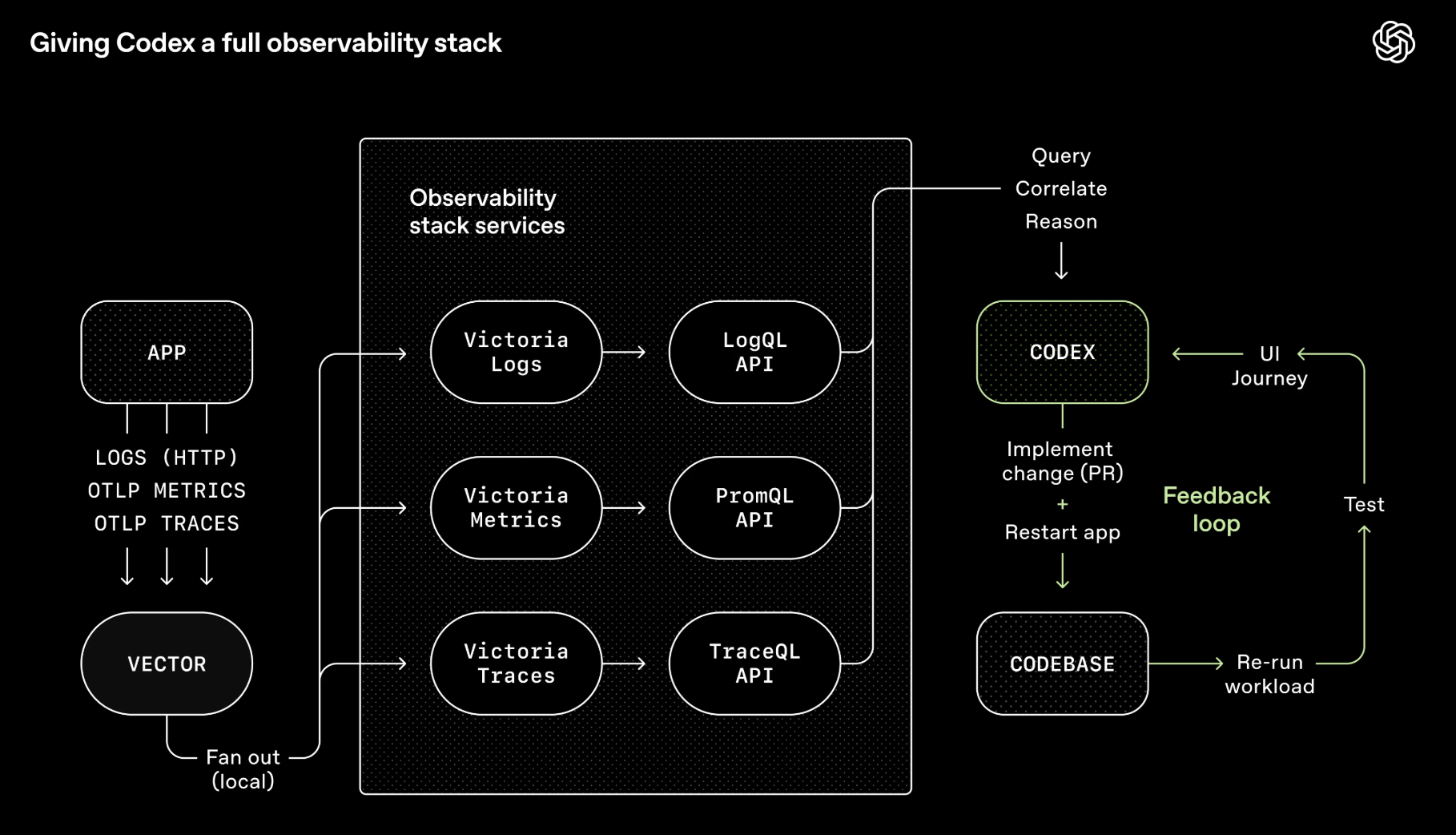
Команда OpenAI Codex подключила Chrome DevTools, инструменты наблюдаемости и браузерную навигацию прямо в среду выполнения агента — чтобы агент мог делать скриншоты, ходить по UI, читать логи и сам проверять исправления. По одному промпту агент воспроизводит баг, записывает видео и реализует исправление. Потом — проверяет через приложение, открывает PR, отвечает на ревью и мёржит, передавая задачу человеку только тогда, когда нужна его оценка.
Агент не просто пишет код. Он видит, что этот код делает, и итерирует — как человек.
Моя команда делает голосовых и чат-агентов для техподдержки. Я написал CLI-инструмент converse, который позволяет любой LLM общаться с нашим бэкенд-эндпоинтом и вести пошаговые диалоги. LLM меняет код, тестирует диалоги через converse на живой системе и итерирует. Иногда такие циклы самоулучшения длятся часами.
Особенно мощно это работает, когда результат поддаётся верификации: диалог должен идти по определённому сценарию или вызывать конкретные инструменты в конкретных ситуациях — например, переключать на живого оператора.
Концепцию, которая это обеспечивает, называют обратным давлением (backpressure): автоматические механизмы обратной связи — система типов, тесты, линтеры, pre-commit хуки — которые позволяют агентам замечать и исправлять ошибки без участия человека. Хотите автономности — нужно обратное давление. Иначе получите машину по производству мусора.
Это касается и безопасности. CTO Vercel утверждает, что агенты, генерируемый ими код и ваши секреты должны находиться в разных доменах доверия — потому что промпт-инъекция, спрятанная в лог-файле, может заставить агента слить ваши учётные данные, если всё живёт в одном контексте безопасности. Границы безопасности — тоже обратное давление: они ограничивают то, что агент может сделать, сходя с рельсов, а не только то, что он должен делать.
Два совета:
- Проектируйте под пропускную способность, а не под идеальность. Когда каждый коммит должен быть безупречным, агенты зависают на одном баге и перетирают исправления друг друга. Лучше допускать мелкие неблокирующие ошибки и делать финальный прогон по качеству перед релизом. Для людей мы так и делаем.
- Ограничения > инструкции. Пошаговые промпты («сделай A, потом B, потом C») устаревают. По опыту, задавать границы эффективнее, чем выдавать чеклисты: агенты зацикливаются на списке и игнорируют всё, что в него не попало. Лучший промпт: «вот что я хочу — работай, пока все эти тесты не пройдут».
Вторая сторона инженерии окружения — убедиться, что агент может ориентироваться в репозитории без вас. Подход OpenAI: держите AGENTS.md примерно на 100 строк как оглавление, указывающее на структурированную документацию в других местах. И сделайте актуальность документации частью CI — вместо редких обновлений, которые всегда устаревают.
Когда всё это выстроено, возникает закономерный вопрос: если агент может проверять свою работу, ориентироваться в репозитории и исправлять ошибки без вас — зачем вообще сидеть за компьютером?
Уровень 7: Фоновые агенты
Смелое утверждение: режим планирования умирает.
Борис Черны, создатель Claude Code, до сих пор начинает 80% задач в режиме планирования. Но с каждым поколением моделей процент успешных задач без него растёт. Думаю, мы приближаемся к точке, где режим планирования как отдельный шаг с человеком сойдёт на нет. Не потому что планирование не нужно, а потому что модели учатся планировать сами.
Важная оговорка: это работает только если вы проделали работу на уровнях 3–6. Если контекст чистый, ограничения явные, инструменты хорошо описаны и циклы обратной связи настроены — модель планирует надёжно без вашей проверки. Если нет — придётся контролировать план вручную.
Уточню: планирование как практика никуда не уходит. Оно просто меняет форму. Для новичков режим планирования остаётся правильной точкой входа (как описано на уровнях 1 и 2). Но на уровне 7 «планирование» для сложных задач — это уже не написание пошаговых инструкций. Это исследование: изучение кодовой базы, прототипирование вариантов в отдельных worktree, картирование пространства решений. И всё чаще это исследование за вас проводят фоновые агенты.
Вот почему это открывает фоновых агентов. Если агент может сформировать качественный план и выполнить его без вашего одобрения — он может работать асинхронно, пока вы занимаетесь другим. Это критический переход: от «нескольких вкладок, которые я жонглирую» к «работе, которая идёт без меня».
Цикл Ральфа — популярная точка входа: автономный агентный цикл, который раз за разом запускает coding-CLI, пока все пункты PRD не выполнены. Каждая итерация — новый экземпляр с чистым контекстом. По опыту, цикл Ральфа сложно отлаживать, и любая неточность в PRD прилетает бумерангом. Слишком «запусти и забудь».
Можно запускать несколько циклов Ральфа параллельно, но чем больше агентов — тем яснее видно, на что на самом деле уходит время: координация, выстраивание порядка, проверка результатов, подталкивание процесса. Вы больше не пишете код — вы стали менеджером среднего звена.
Нужен агент-оркестратор, который берёт на себя диспетчеризацию — и вы фокусируетесь на намерении, а не на логистике.

Инструмент, который я активно для этого использую, — Dispatch, мой навык для Claude Code, превращающий сессию в командный центр. Вы остаётесь в одной чистой сессии, пока рабочие агенты делают тяжёлую работу в изолированных контекстах. Диспетчер планирует, делегирует и отслеживает, сохраняя основное контекстное окно для оркестрации. Когда рабочий агент застревает — он задаёт уточняющий вопрос, а не падает молча. Dispatch работает локально — идеально для быстрой разработки: быстрая обратная связь, интерактивная отладка, никаких инфраструктурных накладных расходов.
Inspect от Ramp — дополняющий подход для более длительной и автономной работы: каждая агентная сессия запускается в облачной песочнице — виртуалке с полной средой разработки. Продакт замечает UI-баг, пишет о нём в Slack, и Inspect подхватывает и работает, пока ваш ноутбук закрыт. Компромисс — операционная сложность: инфраструктура, снапшоты, безопасность. Зато масштаб и воспроизводимость, которых локальные агенты не дадут. Мой совет — используйте оба: локальные и облачные фоновые агенты.
Один паттерн, который оказался неожиданно мощным на этом уровне: разные модели для разных задач. Лучшие инженерные команды — не из клонов. Они из людей с разным мышлением, опытом и сильными сторонами. Та же логика работает и для LLM. Модели прошли разное дообучение и имеют разные склонности. Я регулярно направляю Opus на реализацию, Gemini — на исследование, Codex — на ревью. Совокупный результат сильнее, чем любая модель в одиночку. Мудрость толпы, только для кода.

Критически важно: разделяйте исполнителя и ревьюера. Я убеждался в этом на горьком опыте: если один и тот же экземпляр модели пишет и оценивает свою работу — он предвзят. Он будет замалчивать проблемы и рапортовать, что всё готово, когда это не так. Не злой умысел — та же причина, по которой вы не проверяете собственную контрольную. Поручите ревью другой модели или другому экземпляру с промптом для ревью. Качество сигнала резко вырастет.
Фоновые агенты открывают и другой шлюз: AI в CI-пайплайне. Когда агенты умеют работать без человека — запускайте их из существующей инфраструктуры:
- Бот документации — перегенерирует документацию при каждом мёрже и создаёт PR для обновления CLAUDE.md (мы так делаем, колоссальная экономия времени).
- Ревьюер безопасности, который сканирует PR и создаёт исправления.
- Бот зависимостей — реально обновляет пакеты и прогоняет тесты, а не просто создаёт тикеты.
Хороший контекст, накапливаемые правила, мощные инструменты, автоматические циклы обратной связи — всё это теперь работает автономно.
Уровень 8: Автономные агентные команды
Этот уровень пока никто полностью не освоил, хотя несколько команд движутся в этом направлении. Живой фронтир.
На уровне 7 LLM-оркестратор направляет LLM-рабочих по модели hub-and-spoke. Уровень 8 убирает это узкое место. Агенты координируются напрямую: берут задачи, делятся находками, отмечают зависимости, разрешают конфликты — без единой точки оркестрации.
Экспериментальная функция Claude Code Agent Teams — ранняя реализация: несколько экземпляров работают параллельно над общей кодовой базой, у каждого своё контекстное окно, общаются напрямую. Anthropic использовал 16 параллельных агентов для создания с нуля компилятора C, способного скомпилировать Linux. Cursor запускал сотни одновременных агентов неделями, чтобы создать с нуля веб-браузер и мигрировать собственную кодовую базу с Solid на React.
Но присмотритесь — и увидите швы. Cursor обнаружил: без иерархии агенты становятся избегающими риска и крутятся без прогресса. Агенты Anthropic ломали существующую функциональность, пока не добавили CI-пайплайн с проверкой на регрессии. Все, кто экспериментирует на этом уровне, говорят одно: координация множества агентов — сложная задача, и никто ещё не приблизился к оптимуму.
Честно: я не думаю, что модели готовы к такой автономии для большинства задач. И даже если бы интеллекта хватало — они всё ещё слишком медленные и дорогие по токенам, чтобы это было экономически оправдано для обычных задач. Компиляторы и браузеры впечатляют, но до повседневной практики пока далеко.
Для большинства ежедневных задач рычаг — на уровне 7. Не удивлюсь, если уровень 8 в итоге станет доминирующим — но сейчас я бы вложил энергию в уровень 7 (если вы не Cursor, для которого прорыв — это и есть бизнес).
Уровень ?: Что дальше
Неизбежный вопрос — что дальше. Когда оркестрация агентных команд станет бесшовной, нет причин, по которым интерфейс должен оставаться текстовым. Голосовой интерфейс к вашему coding-агенту — настоящий разговорный Claude Code, а не просто speech-to-text — естественный следующий шаг. Смотришь на приложение, описываешь изменения вслух — и видишь, как они происходят прямо перед тобой.
Есть люди, которые гонятся за one-shot-подходом: сформулировал — ИИ безупречно реализовал за один проход. Проблема в том, что это предполагает, будто мы знаем, чего хотим. Не знаем. Никогда не знали. Разработка ПО всегда была итеративной — и такой останется. Просто станет намного проще, выйдет за рамки чисто текстового взаимодействия и будет чертовски быстрее.
Итак: на каком вы уровне? И что вы делаете, чтобы перейти на следующий?