Бустинг полей и function_score: управление ранжированием
В статье о BM25 мы разобрали, откуда берётся _score. Но BM25 знает только о тексте: частоте слов, их редкости и длине поля. Он не знает, что заголовок важнее описания, что свежая статья лучше трёхлетней или что материал с миллионом просмотров полезнее нулевого. Для этого есть три инструмента: boost в теле запроса, синтаксис ^N в multi_match и function_score.
Boost на уровне запроса
boost — это умножающий коэффициент для отдельного условия. Добавьте его прямо к любому запросу:
GET /articles/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "elasticsearch",
"boost": 3.0
}
}
},
{
"match": {
"body": {
"query": "elasticsearch"
}
}
}
]
}
}
}BM25-скор из ветки title умножается на 3.0, из body остаётся как есть. Документ, в заголовке которого встречается «elasticsearch», окажется выше того, где это слово только в теле.
Если вы используете multi_match — boost на поле пишется через ^:
GET /articles/_search
{
"query": {
"multi_match": {
"query": "elasticsearch поиск",
"fields": ["title^3", "summary^1.5", "body^1"]
}
}
}"title^3" — то же, что boost: 3.0 на поле title. Компактный способ расставить приоритеты по полям.
function_score: полный контроль над скором
Для более сложных сценариев — свежесть, популярность, бизнес-логика — есть function_score. Это обёртка вокруг любого запроса: сначала запрос находит документы и считает BM25-скор, потом одна или несколько функций модифицируют этот скор.
Структура:
GET /articles/_search
{
"query": {
"function_score": {
"query": { "match": { "body": "elasticsearch" } },
"functions": [],
"score_mode": "multiply",
"boost_mode": "multiply"
}
}
}Два ключевых параметра:
score_mode— как объединить результаты нескольких функций друг с другом (multiply,sum,avg,first,max,min)boost_mode— как соединить итог функций с оригинальным BM25-скором. При"multiply"(дефолт): $\text{score}_{\text{final}} = \text{score}_{\text{BM25}} \times f(\text{functions})$
flowchart TD
Q[Запрос: match или bool] --> BM[BM25 score для каждого документа]
F1[Функция 1: gauss] --> SM{score_mode: multiply}
F2[Функция 2: field_value_factor] --> SM
SM --> CM[Объединённый результат функций]
BM --> BM2{boost_mode: multiply}
CM --> BM2
BM2 --> R[_score финальный]weight: простой множитель для категории документов
Самая простая функция — weight. Если документ попадает под filter, его скор умножается на заданный вес; остальные не затрагиваются:
GET /articles/_search
{
"query": {
"function_score": {
"query": { "match": { "body": "поиск" } },
"functions": [
{
"filter": { "term": { "type": "tutorial" } },
"weight": 2.0
},
{
"filter": { "term": { "type": "release-notes" } },
"weight": 0.3
}
],
"boost_mode": "multiply"
}
}
}Туториалы поднимаются вверх, release notes уходят вниз — без какой-либо аналитики текста.
field_value_factor: учёт популярности
Если у документа есть числовой сигнал качества — просмотры, рейтинг, лайки — его учитывают через field_value_factor:
GET /articles/_search
{
"query": {
"function_score": {
"query": { "match": { "body": "elasticsearch" } },
"functions": [
{
"field_value_factor": {
"field": "views",
"factor": 0.1,
"modifier": "log1p",
"missing": 1
}
}
],
"boost_mode": "multiply"
}
}
}Параметры:
field— числовое поле документаfactor— на что умножить значение поля перед modifier: $v = \text{factor} \times \text{field}$modifier— нелинейное преобразование над $v$.log1pвычисляет $\ln(1 + v)$ и сглаживает разрыв между статьёй с тысячей и с миллионом просмотровmissing— значение по умолчанию, если поле отсутствует
Почему именно log1p? Без него статья с $1\,000\,000$ просмотров получит в $1\,000$ раз больший буст, чем статья с $1\,000$, и текстовая релевантность исчезнет. С log1p: $\ln(1 + 1\,000\,000) \approx 13.8$, а $\ln(1 + 1\,000) \approx 6.9$ — разница в $2$ раза вместо $1\,000$.
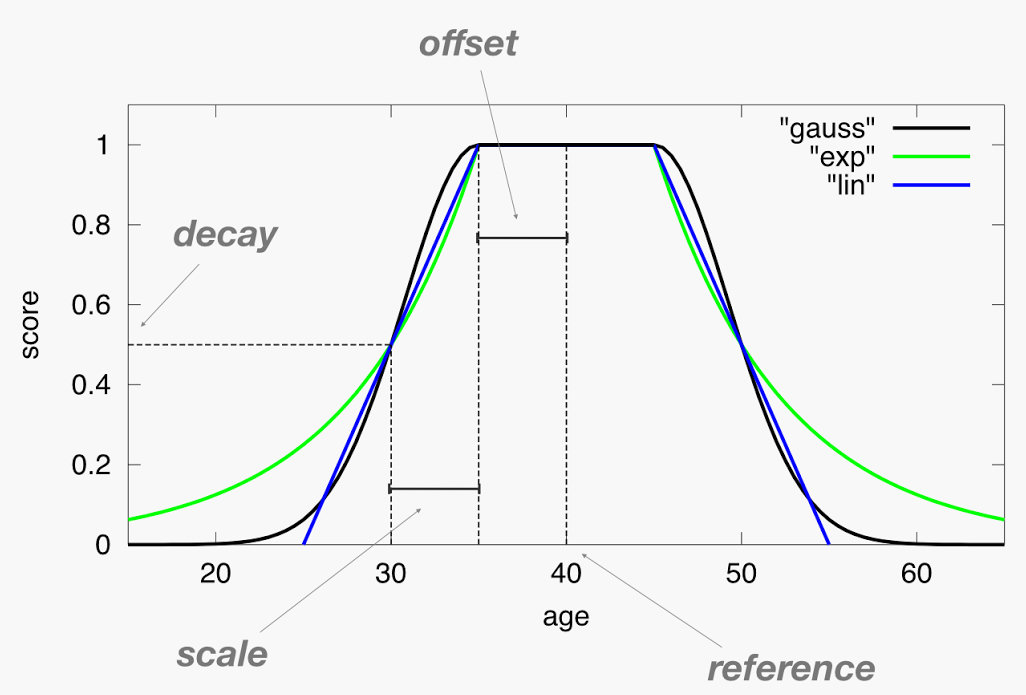
Decay-функции: учёт свежести
Для свежести или «близости» (дата публикации, геопозиция) — функции затухания: gauss, linear, exp. Чем дальше документ от «идеальной» точки, тем ниже его множитель.
GET /articles/_search
{
"query": {
"function_score": {
"query": { "match": { "body": "elasticsearch" } },
"functions": [
{
"gauss": {
"published_at": {
"origin": "now",
"scale": "30d",
"offset": "7d",
"decay": 0.5
}
}
}
],
"boost_mode": "multiply"
}
}
}Параметры:
| Параметр | Смысл |
|---|---|
origin | «Идеальная» точка; документы у origin получают множитель 1.0 |
offset | Зона без штрафа. В пределах offset от origin — множитель 1.0 |
scale | Расстояние за пределами offset-зоны, на котором множитель равен decay |
decay | Целевой множитель на дистанции scale. При 0.5 — половина веса |
Форма кривой у трёх функций разная:
gauss— плавный колокол, наиболее популярный вариантlinear— прямая линия, жёстко обрезается в ноль на краюexp— экспоненциальный спад: быстрый штраф рядом с offset, медленный вдали
Комбинируем: BM25 + свежесть + популярность
Несколько функций в одном function_score работают в два шага: score_mode объединяет их между собой, boost_mode применяет итог к BM25-скору.
GET /articles/_search
{
"query": {
"function_score": {
"query": { "match": { "body": "elasticsearch поиск" } },
"functions": [
{
"gauss": {
"published_at": {
"origin": "now",
"scale": "30d",
"offset": "7d",
"decay": 0.5
}
}
},
{
"field_value_factor": {
"field": "views",
"factor": 0.1,
"modifier": "log1p",
"missing": 1
}
}
],
"score_mode": "multiply",
"boost_mode": "multiply"
}
}
}Итоговая формула:
Это типичная архитектура продуктового поиска: текстовая релевантность как фундамент, сигналы качества — как поправочные коэффициенты.
Несколько практических замечаний
Добавляйте "explain": true при отладке. Из предыдущей статьи вы уже знаете, как читать _explanation — для function_score она также покажет, какая функция и сколько добавила к скору.
Не ставьте boost больше 10–15 без измерений на реальных данных. Экстремальные значения убивают текстовую релевантность: документ с нужной категорией, но нерелевантным текстом всплывёт наверх.
function_score не кешируется — в отличие от условий в filter context. На горячих путях держите тяжёлые фильтры в bool.filter, а function_score применяйте там, где действительно нужен кастомный скоринг.
Полностью произвольная логика — script_score с Painless-скриптом. Очень гибко, но медленнее встроенных функций.