
Что такое Elasticsearch
Elasticsearch — это распределённый поисково-аналитический движок на базе Apache Lucene. Всё общение с ним — через REST API, все данные и запросы — в формате JSON. Если вы уже работали с HTTP и JSON в бэкенде, протокол покажется знакомым: те же методы GET/POST/PUT/DELETE, только вместо вашей бизнес-логики — мощный поисковый движок.
Слово «распределённый» означает, что ES изначально проектировался для работы на нескольких серверах. Данные делятся на шарды, шарды распределяются по нодам (серверам) — это позволяет горизонтально масштабироваться и хранить терабайты данных. Подробнее об этом — в статье Кластер, ноды, шарды и реплики.
Apache Lucene внутри
Lucene — это Java-библиотека для полнотекстового поиска, существующая с 1999 года. Её главная структура — инвертированный индекс: по каждому слову хранится список документов, в которых оно встречается. Именно это позволяет за миллисекунды находить нужные документы среди миллионов.
Elasticsearch оборачивает Lucene в удобный REST-сервис и добавляет поверх него распределённость, репликацию и богатый язык запросов. Один шард Elasticsearch — это буквально один индекс Lucene. Как именно работает этот индекс — разобрано в статье Инвертированный индекс и движок Lucene.
flowchart LR
Client["HTTP-клиент (curl / Kibana)"] -->|"REST API (JSON)"| ES["Elasticsearch"]
ES --> S1["Шард 1 (Lucene)"]
ES --> S2["Шард 2 (Lucene)"]
ES --> SN["Шард N (Lucene)"]Где применяют Elasticsearch
Несколько реальных сценариев, на которые ориентирован этот справочник:
Полнотекстовый поиск по сайту или каталогу. Пользователь пишет «чёрные кроссовки найк» — и находит товары, где встречаются эти слова в разных формах. ES анализирует текст: понимает морфологию, синонимы, близкие варианты написания.
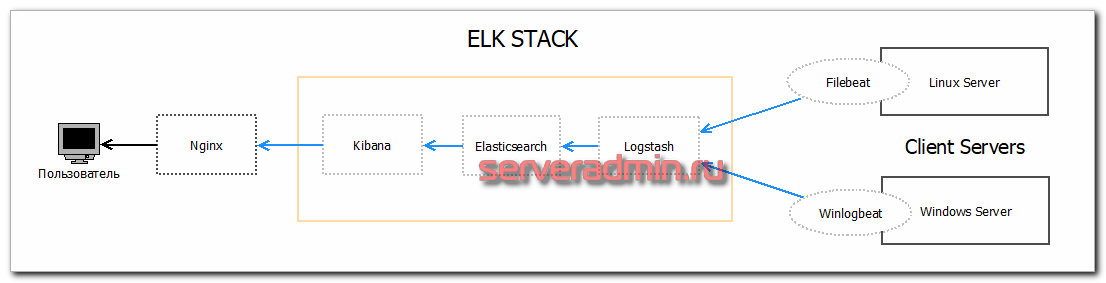
Логи и мониторинг. Классика — стек ELK (Elasticsearch + Logstash + Kibana). Миллионы строк логов прилетают в секунду, и нужно мгновенно найти все ошибки от конкретного пользователя за последние 10 минут.
Векторный и семантический поиск. ES 8 поддерживает поиск по смысловой близости: запрос «ноутбук для программиста» может найти описания без единого из этих слов, но близкие по смыслу. Об этом — в статьях Векторный поиск: поле dense_vector и запрос kNN и ELSER и разреженные векторы для семантики.
Аналитика и агрегации. Посчитать количество заказов по категориям, построить гистограмму продаж по дням, найти топ-10 популярных товаров — ES умеет это через агрегации, прямо поверх тех же индексов, что используются для поиска.
Чем ES отличается от обычной базы данных
Раз вы знакомы с бэкенд-разработкой, вы наверняка работали с PostgreSQL или MySQL. Вот ключевые отличия:
| Характеристика | PostgreSQL / MySQL | Elasticsearch |
|---|---|---|
| Транзакции | ACID | Нет классических ACID |
| Видимость записей | Немедленно (в транзакции) | Через ~1 секунду (near real-time) |
| Основная сила | Надёжное хранение, связи между данными | Полнотекстовый поиск, аналитика |
| Типичная роль | Источник истины | Поисковый / аналитический слой |
Правило на практике: ES — не замена основной базе данных, а дополнение к ней. Данные хранятся в PostgreSQL (источник истины) и дублируются в ES для быстрого поиска.
flowchart TD
User["Пользователь"] -->|"поисковый запрос"| App["Бэкенд-приложение"]
App -->|"CRUD (источник истины)"| DB[("PostgreSQL")]
App -->|"индексация для поиска"| ES[("Elasticsearch")]
ES -->|"результаты"| App
App -->|"ответ"| UserNear real-time: документ появляется в поиске не сразу
Вот поведение, которое удивляет большинство новичков. Вы записали документ в ES — и тут же пытаетесь его найти поисковым запросом. Документа нет. Подождали секунду — нашёлся.
ES не обновляет поисковый индекс при каждой записи — это было бы слишком дорого. Вместо этого он накапливает изменения и делает refresh примерно раз в секунду. После refresh новые документы становятся видны в поиске.
Это и называется near real-time (NRT) — «почти реальное время». Для большинства поисковых сценариев задержка в 1 секунду незаметна. Если нужна мгновенная видимость, можно вызвать refresh явно:
# Записываем документ
POST /products/_doc/1
{
"name": "Ноутбук Lenovo IdeaPad",
"price": 79990
}
# Документ записан, но поиск его ещё не «видит».
# Явный refresh — документ станет виден немедленно:
POST /products/_refreshES — не источник истины
Из NRT и отсутствия ACID-транзакций следует важный вывод: ES нельзя использовать как единственное хранилище данных. При сбое ноды данные могут оказаться в несогласованном состоянии. ES не даёт тех же гарантий надёжности, что реляционная СУБД с журналом транзакций (WAL).
Здоровая архитектура выглядит так: если вы в любой момент можете переиндексировать данные из основной БД в ES — архитектура правильная. ES — это поисковый индекс над вашими данными, а не их единственная копия.
Первый запрос: убедиться, что ES живой
Если ES уже запущен (как это сделать — в статье Способы развернуть Elasticsearch 8: Docker, Elastic Cloud, self-managed и ECK), самый простой запрос — спросить у него о себе:
curl -X GET "https://localhost:9200" \
-u elastic:<ваш_пароль> \
--cacert /path/to/http_ca.crtВ ответ придёт JSON примерно такой структуры:
{
"name": "my-node",
"cluster_name": "my-cluster",
"version": {
"number": "8.15.0",
"lucene_version": "9.11.1"
},
"tagline": "You Know, for Search"
}Поле lucene_version сразу показывает версию Lucene — лишнее напоминание о том, что ES — это Lucene плюс слой распределённости и REST поверх него. Слоган «You Know, for Search» — официальный, он существует с первых версий движка.